From CEO’s Office – 16 June 2024
As I went to bed around midnight yesterday, our user base went past 100k – an internal milestone. More importantly, they’re highly engaged, connecting with our purpose
reaching out
with positive emails. We do face bugs but our users have been understanding. Team morale was high. We
increased
our engineering resource. Our Playstore rating was 4.7 out of 5 from 1000+ users. There was a reason to
smile.
I woke up to an absolute horror show - hundreds of negative messages across
the board including on social networks.
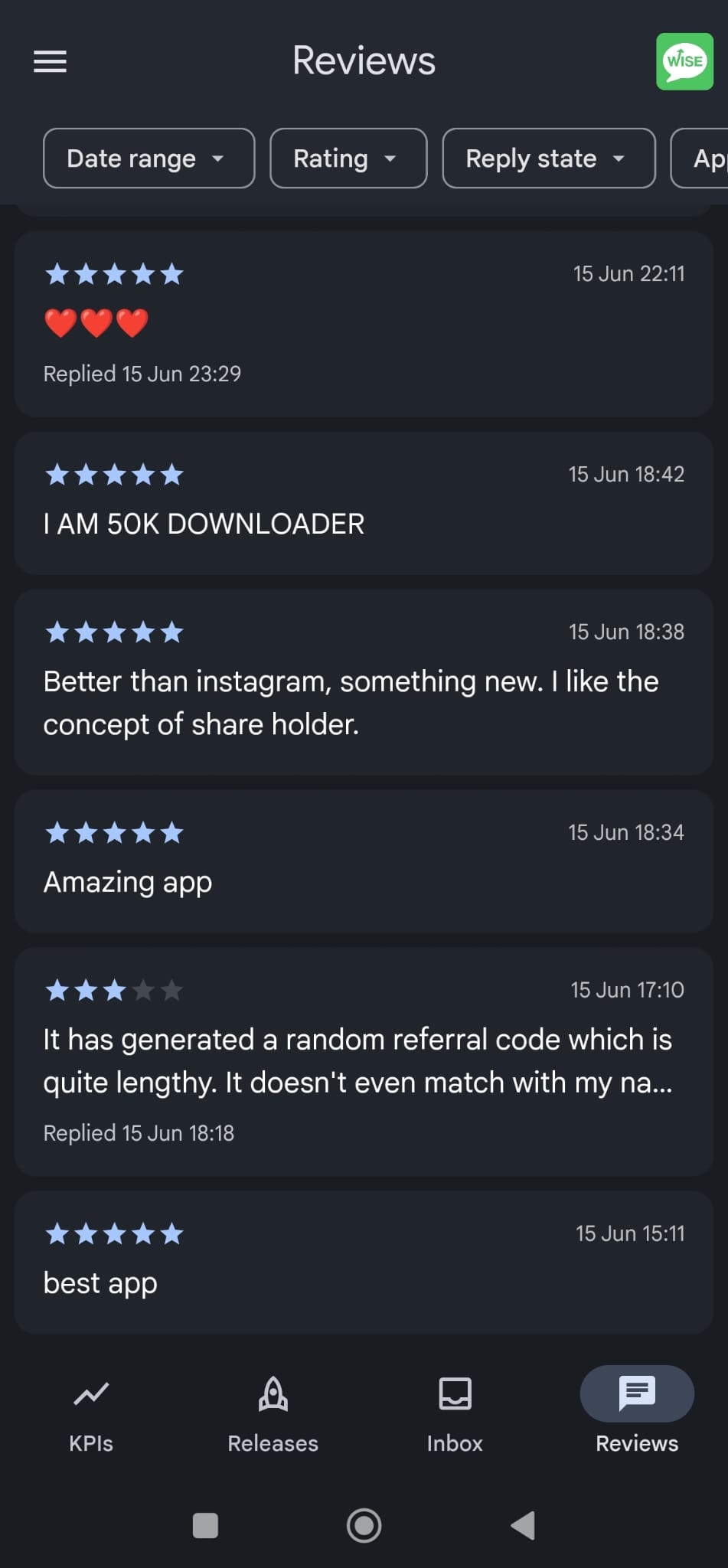
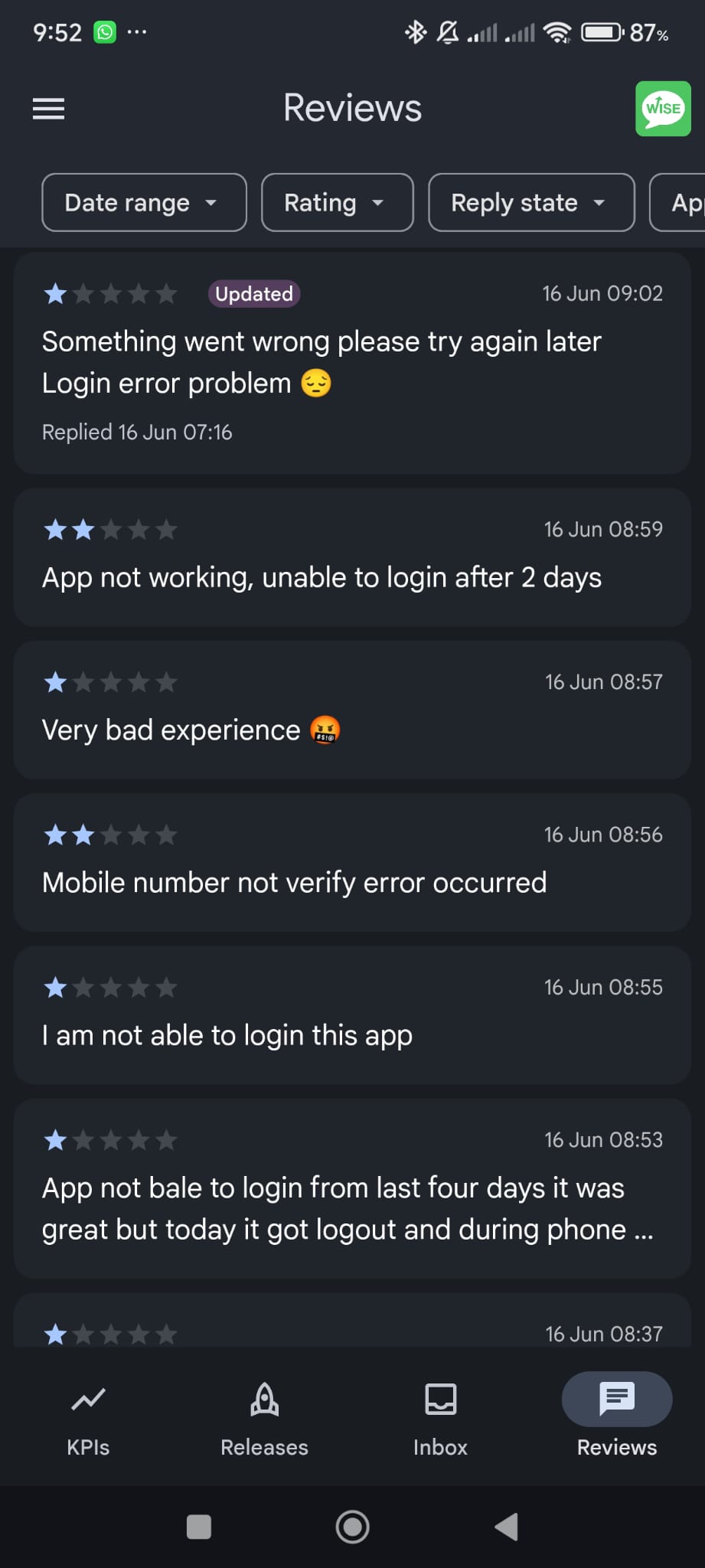
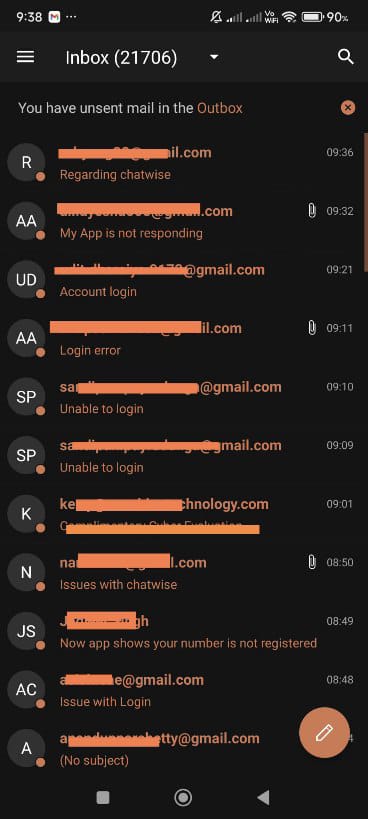
We took our eye off the ball: I slept and turned my phone to ‘do not disturb’
to give myself some rest after 4 days of
significant activity. At 6am on Sunday as we slept in the UK, 10.30am in India, thousands joined
ChatWise and our
servers ran out of space.
Why? Our entire user data sits on the AWS (Amazon Web Services) with security our main priority. One
aspect is also
server space: AWS offers a ‘Managed Service’ which means AWS increases disk space as and when needed,
and
charges our bank account automatically. With my focus to control costs, we had not yet purchased that
service. Our
apps are ‘referral only’ to manage user growth and we check our servers regularly. It was a mistake -
whilst we slept,
servers were overloaded with traffic and crashed. We should have seen it coming.
Users have a right to be angry: We should have done better. Our team has been on a rollercoaster from
extremely
positive loving messages, to extreme negativity. We’re a young company but we’re learning quickly. Last
few days our
focus turned to fixing user reported bugs, improving algorithm & user interface, we took our eye off the
server space.
This will not happen again.
Playstore Ratings With 80% users on Android, our Playstore rating is extremely important: we reply every
single
message. I watched in horror as our rating tanked this morning with negative messages coming every few
minutes
and continued for hours. Even users who had given us 5* rating were turning against us. Issue was also a
lack of
communication – a misleading message was displayed to users while our engineers were fixing the issue.
servers were overloaded with traffic and crashed. We should have seen it coming.
Issue has just been fixed Our engineers fixed it in 3 hours, all services are running normal now. We
will today purchase
an AWS managed service to ensure this does not repeat. We are a young team and we’re learning quickly.
We are
sorry. I am sorry.
For all returning users we will award 5 additional shares as a gesture of goodwill - please wait while
we process this
change. You are our partners in this journey, we need your support now.
End